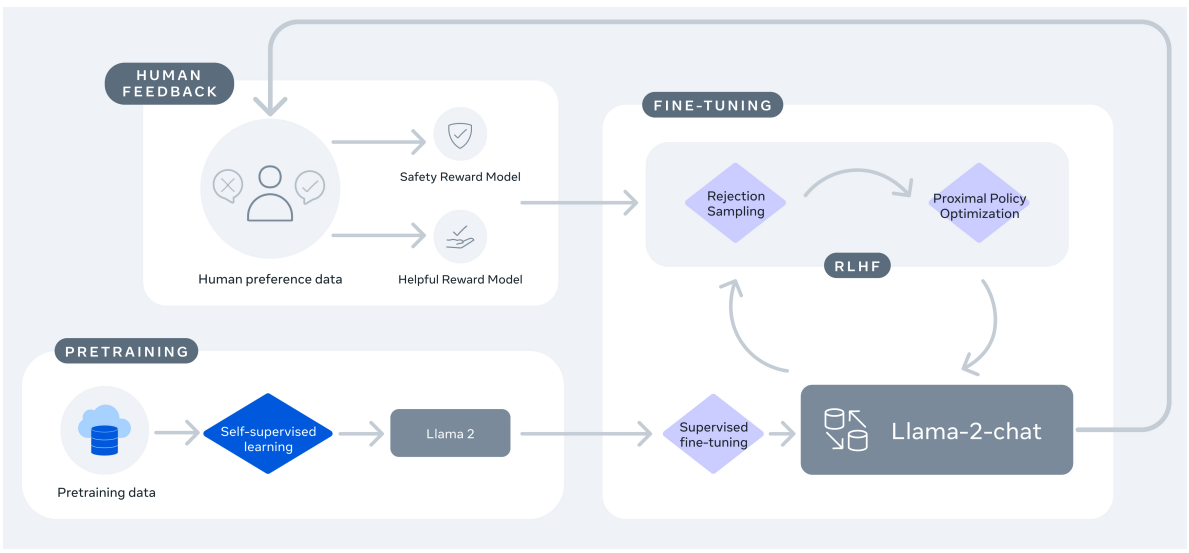
Pre-training
数据
- 对数据源进行了限制, 只从具有很高真实性的数据源中获取数据, 并进行 up-sampling, 增强知识, 抑制幻觉
数据规模
2T tokens.
训练细节
模型结构细节
- Pre-Norm with RMSNorm
- SwiGLU activation function
- RoPE
- GQA, grouped-query attention
训练参数
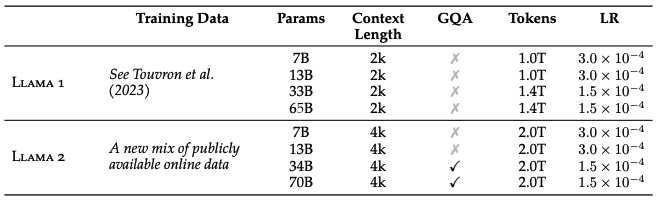
训练使用的 learning rate 和 context length 因模型大小而异, 详情见下图
- 优化器 AdamW, $\beta_{1}=0.9$, $\beta_{2}=0.95$, $\varepsilon=10^{-5}$, $\text{weight decay}=0.1$
- Warmup: 2000 steps
- Cosine learning rate schedule, 最终学习率衰减到最大学习率的 10%
- Gradient clipping: 0.1
- Learning rate:
- 7B: $3 \times 10^{-4}$
- 13B: $3 \times 10^{-4}$
- 34B: $1.5 \times 10^{-4}$
- 70B: $1.5 \times 10^{-4}$
- 词表大小: 32k
最终损失降低到:
- 7B: 1.75
- 13B: 1.77
- 34B: 1.57
- 70B: 1.50
SFT
数据收集
人工编写 Prompt + Answer, 收集了 27540 高质量的 SFT data. 高质量数据包括两大类:
- helpfulness. 样本的 response 确实可以解决 prompt 的任务
- safety. 对于不安全的 prompt 拒绝回答
Meta 在 SFT 这一步, 只收集了 20k+ 量级的. 做出这个决策的原因是, 在使用这个量级的数据 SFT 之后, 模型的输出, 与人类标注的质量可以相比较. 因此团队认为 SFT 的标注工作可以结束, 将标注资源放在 RLHF 要使用的偏好数据的标注.
训练参数
- Batch Size: 64
- Learning Rate: 2e-5
- Learning Rate Schedule: cosine learning rate schedule
- Sequence Length: 4096
- Weight decay: 0.1
- Epochs: 2
使用了 Packing 策略, 将训练集中所有的 prompts 和 answers 连接在一起后按长度切分, 保证序列长度被完全使用. 使用一个特殊符号作为 prompt 和 answer 的分隔.
RLHF
RLHF 的目标是将模型的输出行为对齐于人类偏好(human preferences)和遵循指令(instruction following).
收集人类偏好数据
收集人类偏好数据(human preference data)来训练奖励模型. 收集的方法如下:
- 人工编写 prompt
- 将编写的 prompt 输入到 SFT 后的模型中, 得到两个输出作为采样, 并为这两个采样标注哪个回答更好
- 为了让采样更具有多样性, 使用同一个 prompt 采样时, 使用不同的模型(model variants)进行采样(猜测是训练了两个 SFT 模型), 并且使用了不同的 temperature.
- 为偏好划分了 4 种标签:
significantly better,better,slightly better,negligibly better/ unsure
偏好标注的关注点, 在与回答的 有用性(helpfulness) 和 安全性(safety) 两个方面, 因此判断四种标签的方法为:
- helpfulness:
LLaMA2-Chat的回答可以满足用户要求, 提供所需的信息 - safety: 模型的回答是否是安全的, 标签被设计为 3 类:
- 选择的回答更安全, 另外的回答不安全. 最终占整个数据集的 18%
- 两个回答都是安全的. 47%
- 两个回答都是不安全的. 35%
两者的标注是分开的. 例如 giving detailed instructions on making a bomb 的回答可以被认为有用, 但是不安全的. 这种分开标注, 相互不纠缠, 有更清晰的标注引导, 标注的质量会更高.
从 safety 的三类标签也能看到, 抛弃了 选择的回答是不安全, 另外的回答是安全的 这种情况, 因为安全的回答才有资格作为更好的答案.
最终收集了 1,418,091 条人工偏好数据.
Safety 偏好数据
safety 方面, 针对性地编写了一些 对抗性的 prompt(adversarial prompts), 从两个角度进行了编写.
Risk category
Risk category, 可以理解为是可能产生不安全内容的潜在主题(topic). LLaMA 2 中划分了三个类别:
- illicit and criminal activities: 各种犯罪行为
- hateful and harmful activities: 歧视, 诽谤, 自残等行为
- unqualified advice: 例如医疗建议, 金融建议, 法律建议等各种严肃建议的场景
Attack vectors
Attack vectors 可以理解为 prompt 的多种提问风格, 这种风格可以诱发模型做出不好的回答. 考虑了以下几种:
- psychological manipulation: 心理操纵
- logic manipulation: 逻辑操纵, 如虚假假设
- syntactic manipulation: 句法操纵, 如故意的错误拼写, 汉语中还有形近字, 音近字, 拆字等攻击
- semantic manipulation: 语义操控, 如隐喻, 阴阳怪气..
- perspective manipulation: 透视操纵, 如不合适的角色扮演
收集-训练迭代
定期收集人工标注数据, LLaMA 2 中每周收集一次.
在收集到更多的人工偏好数据后, 训练得到更好的奖励模型, 再通过 PPO 训练, 得到更好的 Chat 模型.
在得到更好的 Chat 模型之后, 从 Chat 模型中采样得到的数据分布也会发生变化, 这会让模型产生一些新的数据分布. 这些新数据分布, 在下轮的训练中, 会拓宽奖励模型的视野, 提高模型的泛化性和整体性能.
这种一轮轮迭代的方式, 帮助奖励模型的分布不断拓宽, 进而经过 RLHF 的 Chat 模型也进一步提升.
Reward Modeling
有研究发现 helpfulness 和 safety 存在 trade off 的情况, 这会使得用同一个奖励模型, 在这两个评价任务中都得到好的效果, 是非常有挑战性的. 因此, LLaMA 2 分开训练了两个奖励模型: Helpfulness RM 和 Safety RM.
奖励模型使用预训练模型的 checkpoints 作为初始化, 保证模型具备预训练过程中获取的知识, 防止出现奖励模型和 RLHF 训练目标的 Chat 模型, 出现知识不匹配的情况, 进而导致产生幻觉.
训练目标
使用 Binary ranking loss, 目标是让 RM 对偏好的回复产生更高的分数.
$$ \mathcal{L}_{\text {ranking }}=-\log \left(\sigma\left(r_\theta\left(x, y_c\right)-r_\theta\left(x, y_r\right)-m(r)\right)\right) $$
$r_\theta\left(x, y_c\right)$ 代表 Prompt $x$ 和 Chat 模型的 completion $y$ 给到 RM 模型 $\theta$ 得到的标量分数. $y_{c}$ 代表是标注人员更偏好的回复, $y_{r}$ 代表的是被拒绝的回复.
Meta 进一步引入了 margin 成分 $m(r)$. Binary ranking loss 是减函数, 两个 completion 之间的 score 差距越大, 对应的损失就越小, 这也符合直觉. 而在融入减去一个非负的 margin 成分之后, 缩小了 completion 之间的 score 差别, 产生更大的损失, 迫使模型将两者之间的距离拉的更远.
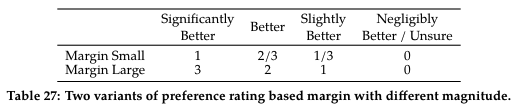
$m(r)$ 是一个离散函数, 它利用了偏好数据的 4 种标签: significantly better, better, slightly better, negligibly better/ unsure, 显式地利用这些标签来对不同差别的 completion 施加不同的 margin 大小, 整体上是对差异更显著的 completion 增加更大的 margin, 以期望拉开更大的差距.
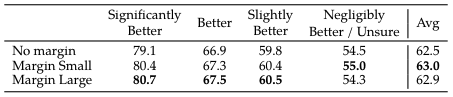
Meta 实验了两套大小不同的 $m(r)$ 离散函数 , 对应于下表中的 Margin Small 和 Margin Large, 实验证明增加的 margin 项确实提升 RM 的性能, 且更大的尺度的 $m(r)$ 对应的效果更好, 但更大尺度的 $m(r)$ 对相近回答的性能有所降低.
$m(r)$ 离散函数详情:
实验结果, 数值代表的是准确率:
训练数据
训练 RM 的数据集, 由上面所收集的人工偏好数据和开源偏好数据集组合而成.
初始时, 由于没有人工数据, 使用开源偏好数据训练得到初版 RM 模型, 同时并行地收集人工偏好数据. 这里有一个矛盾点, RLHF 需要的 reward single, 应当是对 LLaMA 2-Chat 模型的输出进行的学习, 而开源数据是其他模型产生的. 但在论文的实验中, 没有观察到开源数据带来任何的负迁移效果. 因此最终的数据集混合了这些开源数据, 而这些开源数据, 会为 RM 带来更好的泛化性能.
对于生成数据和开源数据这两种数据集, Helpfulness RM 和 Safety RM, 使用了不同的最佳混合比例
- Helpfulness RM 的训练集
- 使用了全部的
人工标注得到的 Helpfulness 数据, 占数据集的一半 - 另外一半是从
人工标注得到的 Safety 数据和开源数据集中采样得到
- 使用了全部的
- Safety RM 的训练集
- 使用了全部的
人工标注得到的 Safety 数据, 以及Anthropic Harmless data, 这部分占整体的 90% - 另外 10% 混合了
人工标注得到的 Helpfulness 数据和开源的 helpfulness 数据集. 混合了这 10% 的 helpfulness 数据集之后, 能够有效的提升 Safety RM 在 chosen 和 rejected 都是安全的样本中的准确率
- 使用了全部的
训练参数
- Epoch: 1, 训练的步数多会导致 over-fitting
- Learning Rate
- 5e-6 for 70B
- 1e-5 for other scales
- Learning Rate Schedule: cosine learning rate schedule, 最低降到 learning rate 的 10%
- Warm-up: 3% total steps
- Batch size: 512 pairs per batch
- Weight decay: 0.1
强化学习
训练策略
Meta 探索了两种 RLHF 中常用的两种微调算法:
- PPO(Proximal Policy Optimization)
- 拒绝采样微调(Rejection Sampling fine-tuning)
这两种 RL 算法的区别在于:
- 拒绝采样对于每个 prompt, 采样出 K 个样本; PPO 只采样一个样本
- PPO 在每一步 policy 模型参数更新后, 对当前训练的 prompt 进行采样; 拒绝采样时在强化学习开始之前, 从初始的 policy 中对所有的 prompt 都进行采样, 一次性采样得到所有输出, 这个其实就是 SFT
Meta 在强化学习这一步, 使用迭代训练的策略. 由于 RM 使用的偏好训练集是一批批采样标注得到的, 使用新标注的数据得到更好的 RM 模型, 并获取更多的 prompts, 这是训练更好的 RLHF 模型的基础. 实际上, Meta 训练了 RLHF-V1 到 RLHF-V5 共 5 个版本的模型.
在包括 RLHF-V4 在内的早期版本中, 只使用拒绝采样进行训练. 在 V5 中, 顺序的使用这两种方法, 先使用拒绝采样方法训练, 再挑选出 Evaluation 最高的 checkpoint, 使用 PPO 继续进行训练.
拒绝采样
拒绝采样的做法
拒绝采样本质上就是在进行 SFT, 只是用来训练的样本是从模型中采样得到的.
拒绝采样这种 RL 方法首先在 70B 规模的 LLaMA2-Chat 模型上进行, 采样得到的样本, 除了用来训练 70B 的模型, 所有更小规模的模型也是用这些数据做拒绝采样的训练, 而不是各个规模的模型各自自己采样. 这样做的目的, 是将大模型的能力蒸馏到小模型中去.
RLHF 共经过了 RLHF-V1 到 RLHF-V5 5 个阶段, 每个阶段的训练中, 对于每个 prompt 样本, 使用上个阶段得到的样本采样 K 个 answers, 并选择当前最优的 RM 进行评价, 得到分数最高的样本. 在早期的探索中, 训练当前阶段使用的样本, 都是用上个阶段的模型采样得到, 例如训练 RLHF-V3 使用的样本全部来自 RLHF-V2 的采样. 但这种方法在整体指标提升的同时, 会导致某些方面能力的退化. 例如通过这种方法训练得到的 RLHF-V3 在编写押韵诗句方面比之前的版本更差.
为了解决这个问题, 每个阶段的训练, 会使用之前所有阶段产生的样本作为候选池, 从中选出 score 最高的一批样本作为训练数据集. 例如, 训练 RLHF-V3 会使用 RLHF-V2 和 RLHF-V1 的样本.
拒绝采样为什么能起作用
为什么这种 SFT 的形式可以用作 RLHF 呢?
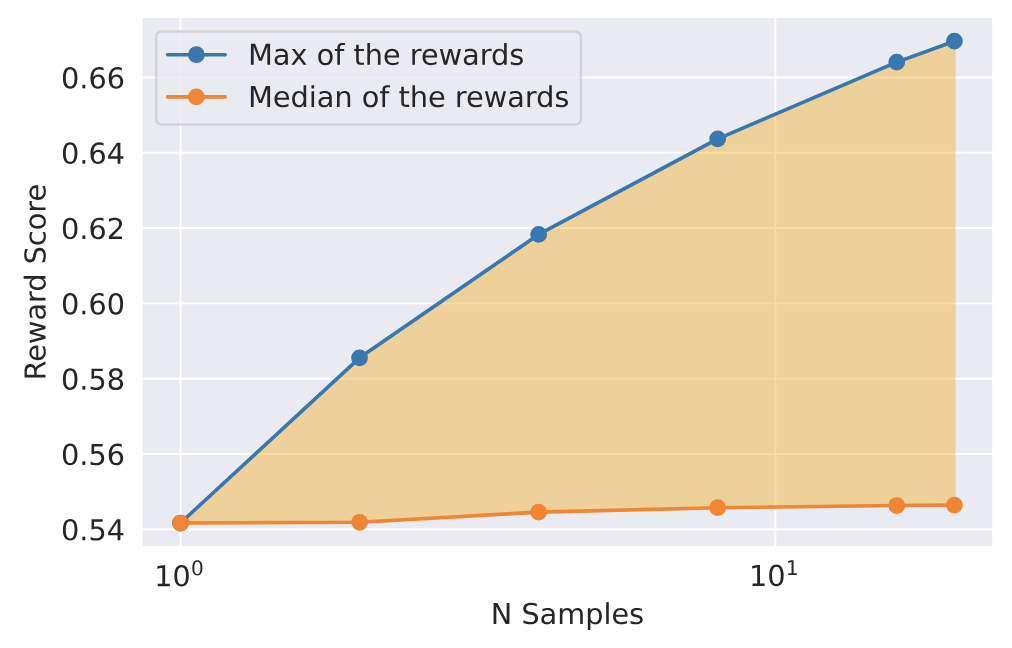
上图呈现了单个 prompt 随着采样数量 N 的增加, 这 N 个采样 reward score 的最大值和中位数的变化情况. 每个点的值是统计训练集中所有 prompt 值的平均得到. 拒绝采样用的是 N 个采样中 score 最大的样本作为训练样本, 对应着图中的蓝线. 而橙色线代表着一次采样的期望值, 因此最大值和中间值之间的 delta 就代表了拒绝采样使用最优采样做 fine-tuning 的潜在收益.
随着单个 prompt 采样量 N 的增加, 这个潜在收益还会逐渐增大, 或者说探索的广度越大, 收益也会越大, 是一种用广度换深度(PPO每次采样后更新模型, 再采样循环的方法可以看做是在深度上进行探索)的策略.
因此温度这个超参数对探索也会起到至关重要的作用, 更高的温度能够让采样结果的多样性增加, 但也不是用最大温度就可以.
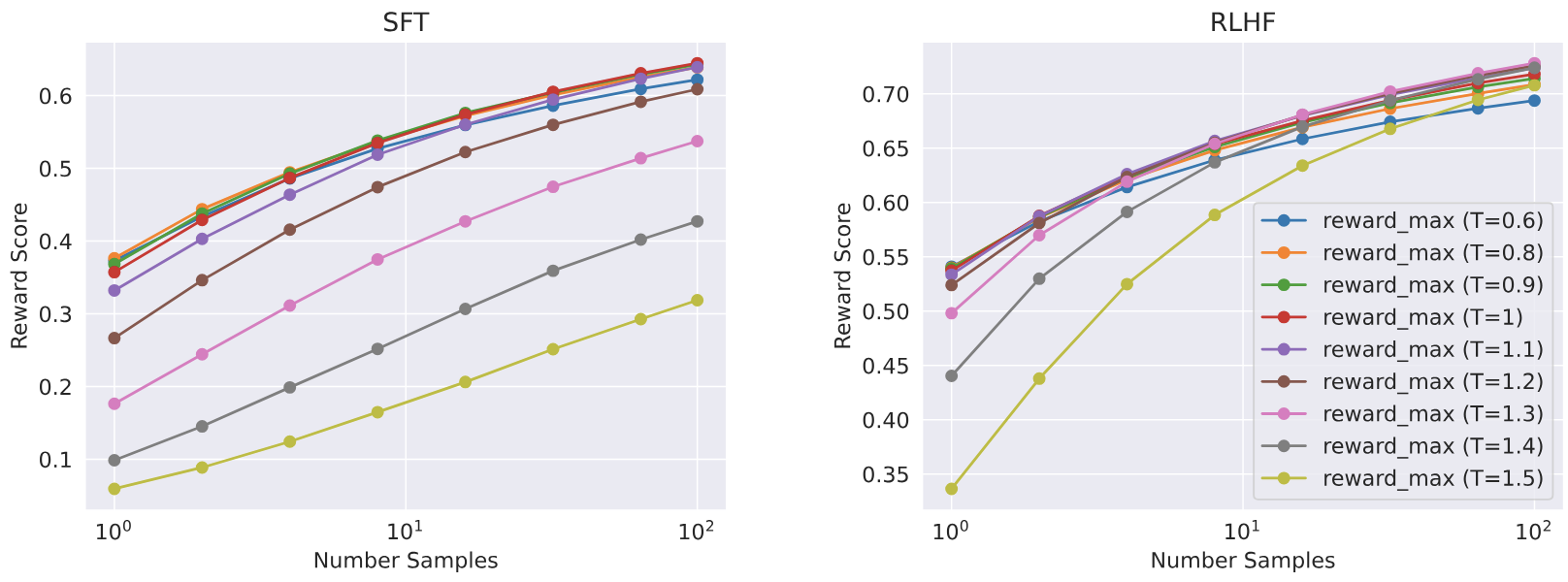
上图反应了 LLaMA2-Chat-SFT 和 LLaMA2-Chat-RLHF 两个模型采样 N 个样本对应的最大 reward score 的曲线, 每条曲线代表着一个采样温度. 可以观察到, 采样的最优温度, 在迭代训练的过程中是在变化的.
因此在每个阶段的 RLHF 模型训练过程中, 每训练一定的步数, 就要暂停下来, 在不同的温度下采样一批, 根据 max reward score 评估当前阶段的最优采样温度.
类似的做法
LLaMA2 中使用的拒绝采样方法, 与 RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment 中提到的方法完全相同.
另外还有 RRHF: Rank Responses to Align Language Models with Human Feedback without tears 方法. 对某一个 prompt, 通过不同的方式(LLM 采样, 人类专家等)生成很多个 answers, 让 RM 去打分, 然后选出好的去 Fine-tune 大模型. 此外, 让大模型也算一下这些 answers 的似然概率当做评分, 让这个评分和RM的打分尽可能对齐, 这个对齐通过设置 Rank loss 进行监督学习来实现.
PPO
PPO 中的 reward function 如下. 这里由于有 Helpfulness RM 和 Safety RM 两种, 所以 reward function 中的 RM score 部分, 需要混合这两个模型的输出.
$$ R(g \mid p)=\bar{R}_c(g \mid p)-\beta D_{K L}\left(\pi_\theta(g \mid p) | \pi_0(g \mid p)\right) $$
其中 $\bar{R}_c(g \mid p)$ 是混合后 RM 的输出, 它的定义如下:
$$ \begin{aligned} & R_c(g \mid p)= \begin{cases}R_s(g \mid p) & \text{if IS\_SAFETY}(p) \text { or } R_s(g \mid p)<0.15 \\ R_h(g \mid p) & \text { otherwise }\end{cases} \end{aligned} $$
$$ \tilde{R}_c(g \mid p)=\operatorname{WHITEN}\left(\operatorname{LOGIT}\left(R_c(g \mid p)\right)\right) $$
其中 $R_s(g \mid p)$ 代表 Safety RM 的输出, $R_h(g \mid p)$ 代表 Helpfulness RM 的输出. 优先考虑安全性. 其中人工编写的 prompt 已经标记了哪些是可能引发不安全回答的, 对应上式中的 $\text{IS\_SAFETY}(p)$, 对于这部分可能引发安全问题的样本, 以及 Safety RM 输出的分数小于 0.15 的阈值的不安全回答, 这两类的不安全情况, 优先考虑安全分数. 0.15 阈值对应的是 Safety RM 0.89 的准确率和在 Meta Safety test set 上 0.55 的召回率.
其他安全的情况, 再考虑 Helpfulness RM 的输出.
在混合了两种 RM 的输出后, $\text{LOGIT}$ 是 sigmoid 的反函数, 再进行白化, 目的是增加稳定性, 与 KL 散度损失项取得合适的平衡.
训练参数
- 使用 AdamW 优化器, 对应的参数为 $\beta_{1}=0.9$, $\beta_{2}=0.95$, $\varepsilon=10^{-5}$, $\text{weight decay}=0.1$
- Gradient clipping 1.0
- Learning rate: 1e-6
- PPO Micro batch size 64, batch size 512, PPO clip threshold 0.2
- 损失函数中的 KL 系数, 在 7B 和 13B 模型中 $\beta=0.01$, 在 34B 和 70B 模型中 $\beta=0.005$
- 不同规模的模型训练步数在 200 到 400 步之间, 并构建了 dev prompts 数据集, 做 early stopping
Multi-Turn 一致性 / Ghost Attention
在对话过程中, 往往会有一个 System Message, 比如要求回复简洁, 或者要求 assistant 扮演一个角色. 期望是这个 System Message, 在整个对话过程中持续作用.
但在最初的 RLHF 迭代中, 得到的模型在经过几轮的交谈后, 就倾向于遗忘最初的 system message 中的要求了.
为了解决这个问题, 提出了 Ghost Attention(GAtt). 这不是一种模型结构, 而是一种调整 fine-tuning 数据的方式.
Ghost Attention
把一个 $n$ 轮的多轮对话记为 $\left[ u_1,a_1,\cdots,u_n,a_n \right]$, 把 system message 定义为 $\text{inst}$. 接下来, 将 $\text{inst}$ 与每轮 user message $u_i$ 拼接起来.
然后使用最新的 RLHF 模型, 对这个多轮对话中每个拼接后的 user message 进行多次采样, 使用 RM 选择最好作为训练样本(拒绝采样的方法). 这样就得到了符合指令的多轮对话数据.
再将除了第一轮之外的所有 user message 中的 $\text{inst}$ 部分删除, 用这个数据进行 fine-tuning.
在训练时, 为了实现多轮以后的 system 指令遵从能力, 将多轮数据中前面几轮中所有 tokens 的 loss 置为 0, 包括原本要计算 loss 的 assistant message 部分.
以上就是 Ghost Attention 的做法.
论文中 system message 从一些任务中合成得到:
- Hobbies, 例如
You enjoy e.g. Tennis - Language, 例如
Speak in e.g. French - Public Figure, 例如
Act as e.g. Napoleon
而 Hobbies 和 Public Figure 合成用到的 list, 是通过 LLaMA2-Chat 生成, 以防止出现模型知识不具备的情况, 会加重幻觉. 而为了让 system instruction 更复杂以及更有多样性, 最终的 instruction 是随机地将上面的几类组合得到. 同时还会将 instruction 进行简化, 例如 Always act as Napoleon from now -> Figure: Napoleon. 使用这些方法, 生成了一个 SFT 数据集, 用这个数据集微调出 LLaMA2-Chat.
总结
SFT的必要性和问题
每个标注人员的创作的 prompt 和 completion 都有很大的多样性, 在这些数据集上进行 SFT, 得到的模型可以学习这种多样性.
这种多样性是很长尾的, 这些长尾数据中也会有很多不好的结果, 这些是 SFT 无法解决的.
RLHF的作用
比较两个 completion 哪个更好, 这个任务相对更简单, 因此 RM 可以很快地学习到将低分分配给效果不好的长尾分布, 使得最差的答案在分布上逐渐被删除. 这一点是通过人类偏好数据标注和 RLHF 训练过程配合得到的.
LLM 超越人类能力的上限, 是通过 RLHF 的人类监督信号得到的, 它比 SFT 更重要.