模型介绍
LWM(Large World Model) 是一个多模态模型, 并且同时支持 1M 的上下文长度. 这里了解这样的模型是怎么训练出来的.
训练方法
Stage 1: 训练长上下文语言模型
第一阶段是训练纯文本模型 LWM-Text 和 LWM-Text-Chat. 上下文长度的扩展是渐进的, 从模型的原生长度到最终的 1M 长度, 中间会训练多个版本不同长度的模型.
训练超长的上下文长度要占用大量的内存, 这里使用两个关键技术, 大幅降低训练长上下文的内存限制:
- RingAttention
- Blockwise Transformer
如何扩增模型的上下文长度
1. 模型结构支持
Ring attention with blockwise transformers for near-infinite context
Blockwise parallel transformer for large context models
由于传统 attention 结构在计算 attention weights 的平方复杂度, 而且现有的各种并行方案(DP, PP, TP)都需要将完整的序列投放到一个节点上, 因此单个节点的内存会限制训练样本的最长长度.
这里需要使用 Blockwise RingAttention, 在序列维度上并行计算, 突破单个节点的内存限制, 这样能处理的长度只受节点数量的限制.
论文中还进行了进一步的效率优化: 将 Blockwise RingAttention 与 FlashAttention 融合, 再结合 Pallas 进一步提升.
2. 逐步训练
Growlength: Accelerating llms pretraining by progressively growing training length
上一步通过 Blockwise RingAttention 突破了单点内存的限制, 但 attention 的平方级别的计算复杂度让计算仍然非常耗时.
为了解决这个问题, 在训练过程中, 逐渐增加序列的长度, 从 32K 逐步增加到 1M tokens 的长度. 直觉上, 先打好 tokens 在 shorter-range 上依赖关系的基础, 然后再扩展到更长的序列上.
由于每个样本的训练时间, 与样本长度成正比, 采用了上面的方案后, 相比与在最长(1M)序列长度上直接训练, 在相同的时间内, 训练的 tokens 总量明显扩大了数量级.
上下文长度扩展的节奏如下:
| Step | Context | Doc Length | Total Examples | Total Tokens |
|---|---|---|---|---|
| 1 | 32k | 10k - 100k | 78k | 7B |
| 2 | 128k | 100k - 200k | 92k | 12B |
| 3 | 256k | 200k - 500k | 37k | 10B |
| 4 | 512k | 500k - 1M | 3.5k | 3B |
| 5 | 1M | 1M+ | 0.8k | 1B |
3. RoPE 位置外推
为了扩展 position embedding 能够在长上下文中有更好的表现, 采用了一种简单的方法, 将 RoPE 中的参数 $\theta$ 根据上下文的长度倍增. 原始版本的 $\theta=10000$. 在这里长度与 $\theta$ 的对应关系为:
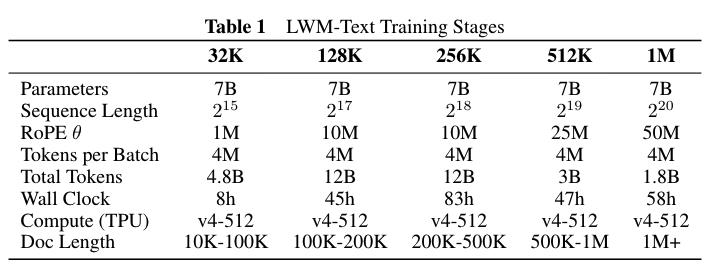
至于为什么简单地增加 $\theta$ 就能够让 RoPE 在长上下文上有好的表现, 先看下面这张图. 这张图的值是 query 和 key 向量之间的 attention scores 期望在不同相对距离上的表现, 蓝色代表 $\theta=10000$, 橙色代表 $\theta=1000000$. 可以看到更大的 $\theta$ 可以防止 attention score 在长距离上的衰减, 从而使得 far-away tokens 也能够对当前的预测产生贡献.
在预训练阶段引入这种方法, 可以让 loss curves 更稳定, 特别是在低学习率上. 更具体的可以参考 Code llama: Open foundation models for code 这篇论文.
如何准备训练数据集
预训练阶段使用数据集来自 The Pile Books3 dataset. 由于每个样本是一本书, 所以数据集中有超长的样本. 每个阶段使用的样本长度不同, 因此需要过滤出相应长度的样本.
训练过程
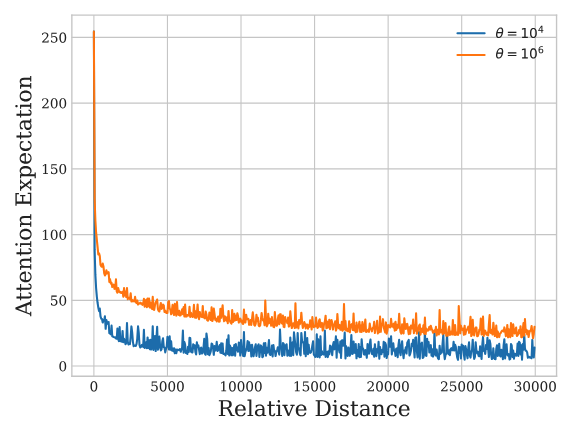
从 LLaMA-2 7B 开始, 下表详细记录了每个阶段训练的详情. 一个阶段训练结束后, 作为下一个阶段的初始化.
长上下文 SFT
用 Book3 数据集完成预训练后, 还需要进行 Chat Fine-tuning 以让模型掌握指令跟随的能力 / 聊天能力.
SFT 数据集准备(重点)
将 Book3 数据集中的样本进行分块(chunk), 每块大小为 1000 个 tokens. 将每个 chunk 通过 prompt 编排后输入到短上下文的 LLM 中生成一个 Question-Answer 对. 得到一批这样的 chunk 和 QA 对组合.
当我们需要对长上下文的预训练模型进行 SFT 时, 例如对 32K 上下文长度的模型, 我们要拼接出一个包含 32K tokens 的样本, 方法将相邻的 chunk 拼接在一起, 并且将这些 chunks 对应的 QA 组织成 Chat 的形式, 拼接在这个样本的最后.
最后采用的数据集来自两部分, 一部分是 UltraChat 数据集, 另一部分是用上面的方法生成的 QA 数据集, 这两部分的比例为 7: 3. 对于 UltraChat 数据集, 也要提前 pack 为训练模型的序列上下文上限的长度, 这点非常重要.
由于 UltraChat 多为短的 chat sequences, 因此 packed 后的样本, 需要计算 loss 的 tokens 的比例是大大超过我们合成的数据集的(要计算 loss 的 tokens 是对话中的 answer 部分, 合成数据集的样本中大部分都是 chunk, 这部分不计算 loss, 统计下来合成数据集的这个比例小于 1%). 所以 UltraChat 和合成数据集中的样本, 一定不要混合在一起进行 packing, 而是要分开 packing.
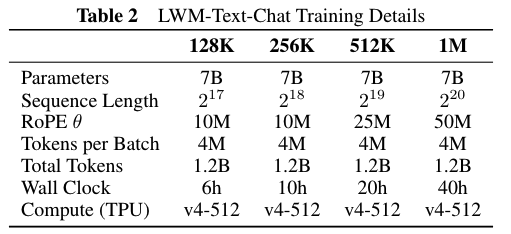
我们在 4 个长度上进行了 SFT 训练, 训练拿对应长度的预训练模型进行初始化.
Stage 2: 训练长上下文的多模态模型
经过 Stage 1 得到训练好的 LWM-Text 和 LWM-Text-Chat, 在 Stage 2 的目标是在 long video and language 序列上完成高效的联合训练.
如何修改模型架构以融合视觉
模型的整体结构如下图所示. LWM 是一个支持 1M tokens 序列的自回归 transformer. 每个视频帧被 tokenize 成 256 个 tokens. 这些视频帧 tokens 与 text tokens 拼接后, 送入到 transformer 中预测下一个 token, 这个 token 可能是 text token 也可能是 vision token.
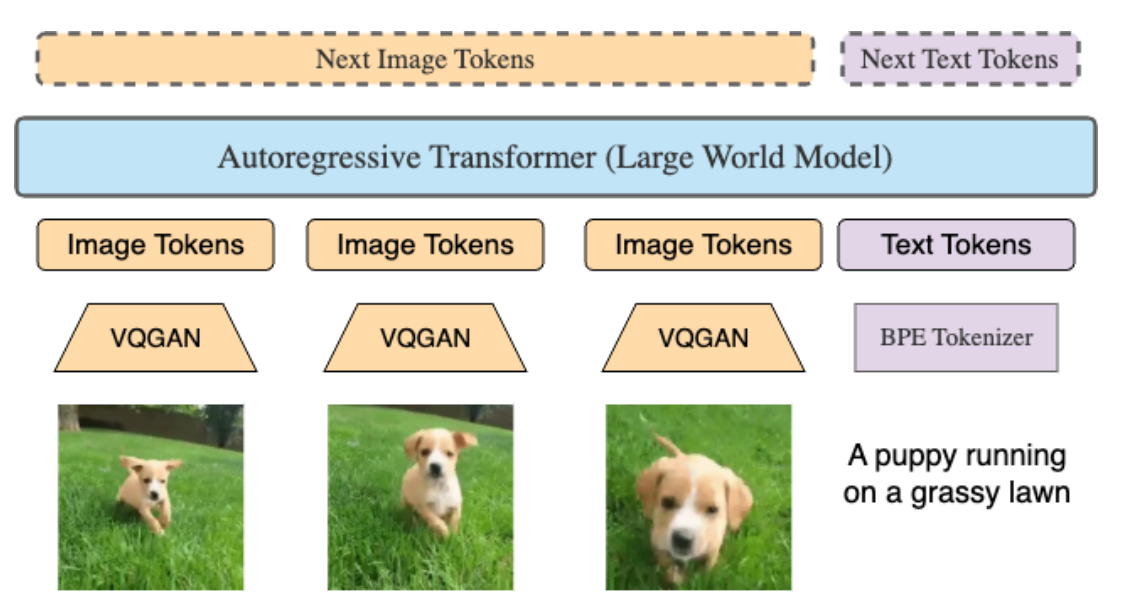
视觉编码器使用的是 VQGAN, 将 $256 \times 256$ 的图片输入 tokenize 成 $16 \times 16$ 的离散 tokens. 对于视频, 使用 VQGAN per-frame 对视频进行 tokenizing.
为了在生成过程中区分两种模态, 知道何时进行切换, 需要标记
- text generation 的结束和 vision generation 的开始
- vision generation 的结束和 text generation 的开始
为此引入, 为了定义视觉生成的结束, 引入了两个新的 mark token:
<eof>, end of frame. 在每个视频帧(除去整个视频的最后一帧)生成后添加<eov>, end of video. 在生成的视频的最后一帧后添加, 以及如果生成的是单张图片, 在生成的图片后也引入这个符号
另外, 为了定义 text generation 的结束, 使用 <vision> 和 </vision> 将 vision tokens 包围住.
需要注意的是 <eof> 和 <eov> 各自对应一个特殊 token, 而 <vision> 和 </vision> 不是特殊 token, 要作为 text 对待, 使用 tokenizer 转化为对应的 tokens.
输入输出中不同类别的 tokens 在训练集中有不同的拼接顺序, 包含:
- image-text
- text-image
- video, 也就是多个 images
- text-video
- text
上面模型的架构图中就是一种 image-text 的拼接形式.
训练过程
使用预训练得到的 LWM-Text-1M 语言模型进行初始化. 而且跟上面训练纯文本的模型一样, 也是分多步, 逐渐扩大多模态模型的上下文长度, 最终得到一个 1M 上下文大小的多模态模型.
这个多步逐渐扩大长度训练的过程, 使用的数据是 text-image 和 text-video 数据的混合. 另外与训练纯文本不同的是, 由于我们用 LWM-Text-1M 进行初始化, 模型已经支持了 1M 上下文的长度, 因此在这里训练多模态能力时, RoPE 的 $\theta$ 就不再使用纯文本中的倍数扩增, 而是使用固定值 $\theta=50\text{M}$. 一个阶段训练结束后, 作为下一个阶段的初始化. 各个阶段训练的情况如下:
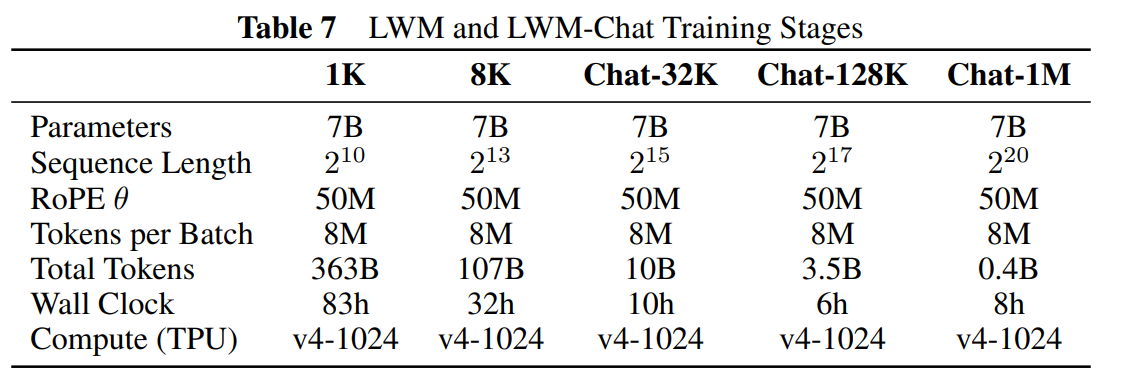
每个阶段使用的训练集如下.
- LWM-1K: 使用的是 text-image dataset, 由 LAION-2B-en 和 COYO-700M 两个数据集混合得到. 过滤掉分辨率不足 256 的样本, 总共收集了大约 1B 个 text-image 数据对
- 在训练过程中, 将 text-image pairs 拼接起来, 并且随机将两种模态的顺序进行交换, 来建模:
- text-image generation 任务
- unconditional image generation 任务
- image captioning 任务
- pack text-image pairs 达到 1K 的 tokens 序列长度
- 在训练过程中, 将 text-image pairs 拼接起来, 并且随机将两种模态的顺序进行交换, 来建模:
- LWM-8K: 使用的是 text-video 训练集, 由 WebVid10M 和 3M InternVid10M 混合得到. 把 images 和 video 看成两种模态的话, 这里的数据集这两种模态各占 50%. 将 30 帧的视频帧转换为 4FPS
- 将 images pack 成 8K 的序列长度
- 同样的, 随机对每个 text-video pair 中两种模态的顺序进行交换
- LWM-Chat-32K/128K/1M: 最后 3 个阶段, 混合了以下四种下游任务分别对应的 chat data:
- text-image generation
- image understanding
- text-video generation
- video understanding
- 其中 text-image generation 和 text-video generation 是从多模态预训练数据中抽取了子集, 并按 chat format 构造了数据集
- image understanding 使用了 ShareGPT4V 中的 image chat instruct data
- video understanding 使用了 Valley-Instruct-73K 和 Video-ChatGPT-100K 两个数据集混合后其中的 instruct data
- 对于 text-image generation, image understanding, text-video generation 这三类 chat data, 属于 short context data, 使用 packing 方法将他们拼接成要训练的上下文长度
- Packing 之后, 在计算 attention 的时候, 要特别注意 mask 的方案, 每个 text-vision pair 只能看到它们自己这对
- 对于 video understanding data, 如果视频太长, 会采样一个满足训练上下文长度的最大数量的帧数
- 在训练过程中, 对于每个 batch, 为 4 个任务各分配 25% 的比例
对于 LWM-1K 和 LWM-8K 这前两个阶段, 还增加混合了 16% 的 pure text data, 使用的是 OpenLLaMA 数据集, 以防止语言能力在多模态训练过程中退化. 混合的方式是一整个 batch 都是 pure text data, 相当于多了 16% 的 pure text batch.